This is a next.js framework site to demonstrate web scraping cases and my expertise in web scraping. Totally 9 scraping cases are presented at this moment, they are handled in API routes with node.js.
There are two main approaches to scraping the web:
- HTTP clients to query the web and data extraction
- headless browsers
For the first approach, we use Cheerio, a library using jQuery on the server side, to crawl web pages. Sites, however, now become increasingly complex, and often regular HTTP crawling won’t suffice anymore, but one needs a full-fledged browser engine, to get the necessary information from a site. This is particularly true for single-page applications which heavily rely on JavaScript and dynamic and asynchronous resources. Browser automation and headless browsers come to deal with the issues. Therefore we use Puppeteer to manipulate the browser programmatically. For the cases in this demonstration, we use either way depending on the actual situations of the target pages.
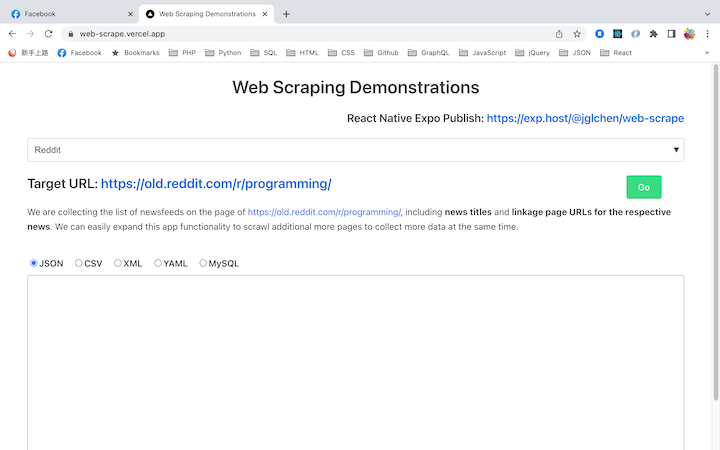
iOS and Android mobile apps are also delivered for the scraping demonstrations. The apps are developed with React Native, anyone who is interested can test the apps through the Expo Publish Link with Expo Go app.